"Behappy": Loneliness Detecting Through Sensing
Chong Yan, Zichen Wang, Zijun Zhang
START
Loneliness is a more and more serious problem in modern society. Recent research has found that young adults who were socially isolated experienced greater feelings of loneliness, and were also more likely to grapple with depression. And substantial evidence now indicates that individuals lacking social connections (both objective and subjective social isolation) are at risk for premature mortality. Though many efforts have been put on this, there is still not a very effective way to detect how people feel lonely.
Most of functions such as detecting are running in the background. So in this section, only the visible parts will be demonstrated.
At the beginning of using this app, users need to firstly input their unique user id.
Then, they can add special locations through either moving the marker or searching the address by inputting key words. After choosing one location, they need to give this location a type.
The last step is to categorize contacts.
Users can update special locations or category of contacts anytime during the trial.
This is a commonly used questionnaire for measuring loneliness levels. A notification will be sent to users every night in order to remind them of completing this questionnaire.

The only visible widget is a "I FEEL LONELY" button. Users are told to click the button when they feel lonely. This is used as another subjective measurment of loneliness.
| Week | Progress |
|---|---|
| Week 5 | Read related works; Design the system; Think of novelties |
| Week 6 | Start building the app |
| Week 7 | Do the testing of the app; Refine the app based on testing; Connect to MySQL databse |
| Week 8 | Collect data |
| Week 9 | Keep collecting data; Analyze data; |
| Week 10 | Keep doing the analysis of data; Prepare for the final demo |
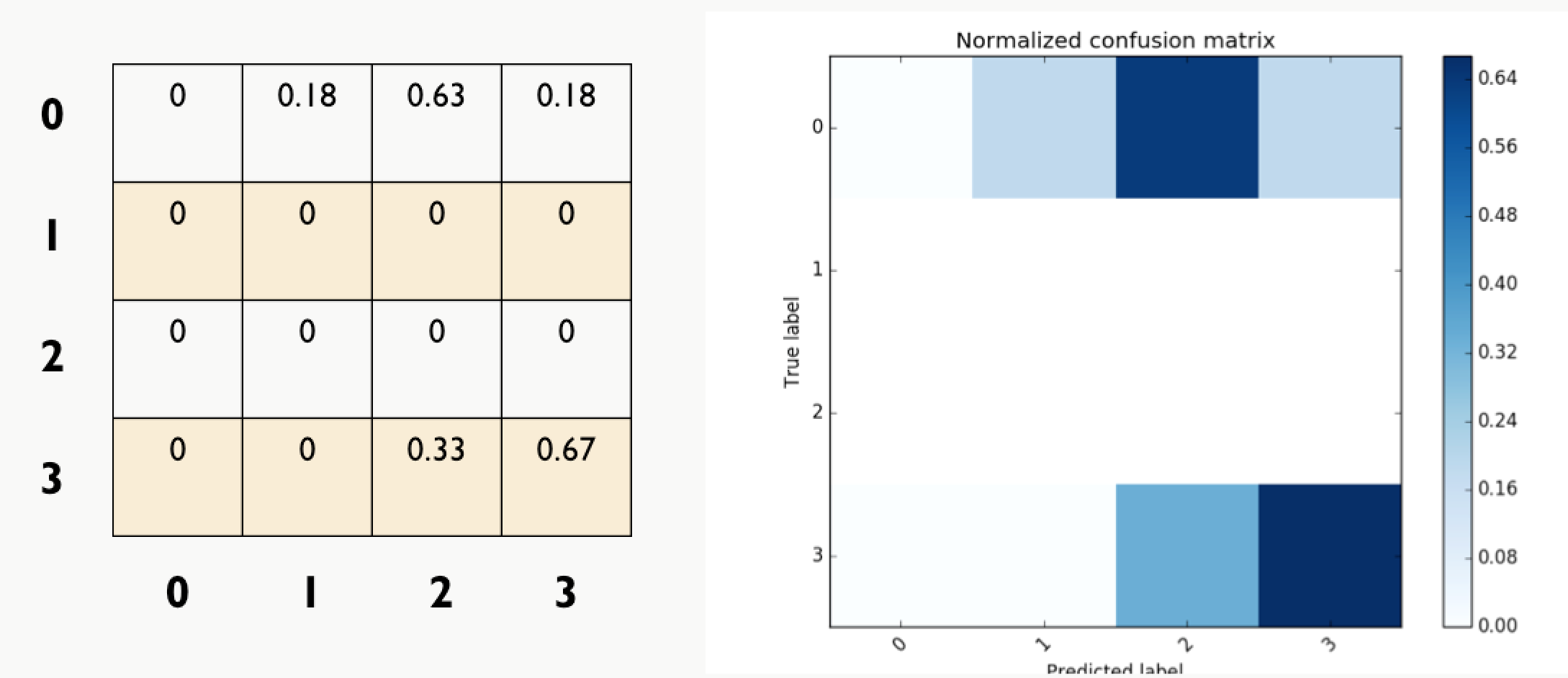
Here are the importance scores for the features we used. From the histogram, we could know that the social network app usage is the most informative feature. Besides, there are four features, whose importance score is greater than the mean importance, namely social network app usage, distance, range and moving duration.
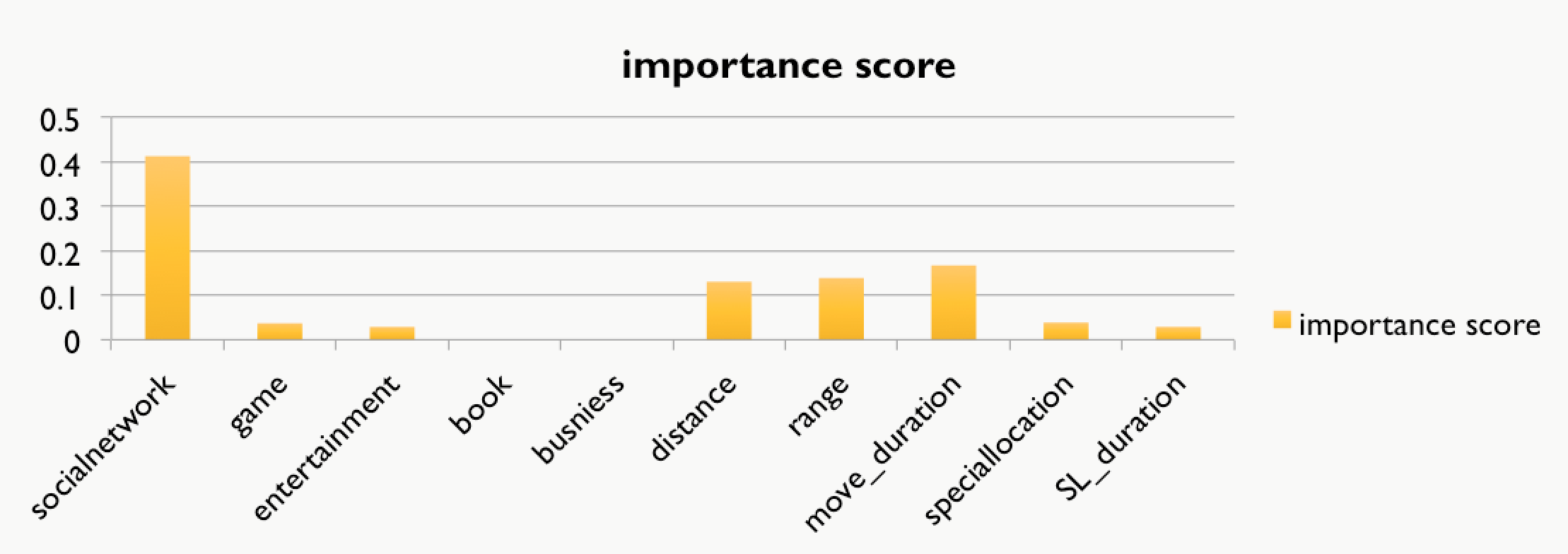
Here are the accuracy of our models. Random forest Classifier has the highest accuracy but it’s still only 57%.
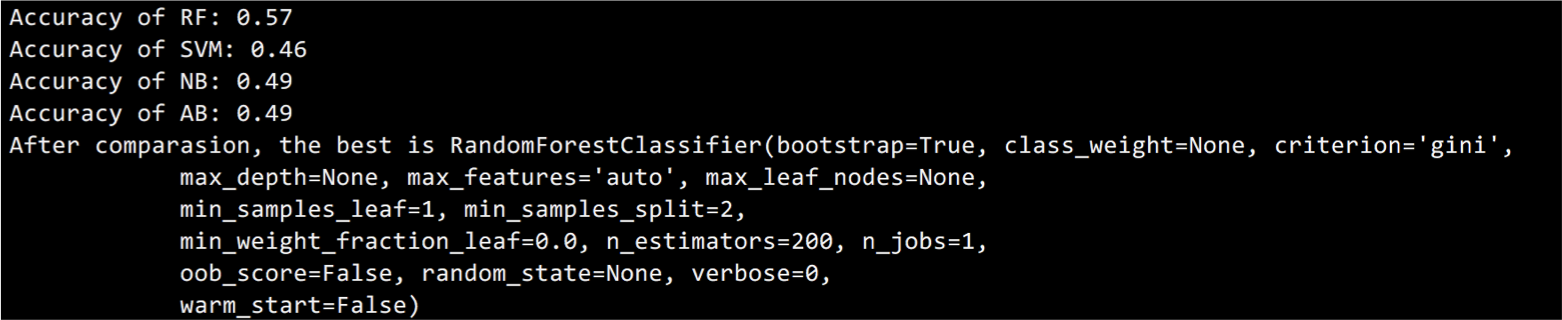
From the confusion matrix, although the accuracy is not high, we noticed that the prediction of the result 3 is most accurate. We think the reason of this phenomenon is that most of the data labeled 3 is based on the I Feel Lonely button, which belongs to self-report data. Comparing to the data labeled by the UCLA questionnaire, these self-report data can train our model better.